Overview of the OpenQuake engine#
This section provides an overview of the OpenQuake engine, its structure and the processes adopted for its development.
Structure of the OpenQuake engine#
The OpenQuake engine is the combination of different and sometimes self-sufficient libraries. Below we provide a short description for each of them.
oq-hazardlib
Contains the code used to describe seismic sources, create the Earthquake Rupture Forecast (ERF), calculate hazard curves, create stochastic event sets, compute ground motion fields and calculate seismic hazard disaggregation.
oq-risklib
Comprises the code used to describe exposure, vulnerability and fragility curves, and for the computation of losses.
oq-nrmllib
Includes the code relating to the reading, writing and validation of the full suite of OpenQuake engine input and output files. The majority of these files are formatted according to a dialect of XML called Natural hazard Risk Markup Language (NRML).
oq-commonlib
Includes common code for OpenQuake engine applications, such as - for example - the code used to describe logic tree structures.
oq-engine
It incorporates the core of the OpenQuake engine; the code in this library acts as the glue that sticks the different libraries together and lets the user easily perform calculations according to an established set of calculation options.
Overview of the OpenQuake engine development process#
The OpenQuake engine is developed through a close and continuous collaboration between the GEM scientific and IT teams. The development process is operated in the open in order to promote the participation of experts working in the disciplines of earthquake hazard and risk analysis, as well as those specialising in software development.
Development tools#
The tools used to maintain and make publicly available the OpenQuake engine repository and to manage the continual improvement and enhancement process are git and a git-based repository hosting service called GitHub. This process ensures comprehensive version control, facilitating the tracking of feature implementation and bug fixing. It also ensures that previous versions of the software can be easily retrieved. When a developer commits new code to the main repository the record of the change is kept. If the code is intended to resolve a bug or error identified in the bug-tracking system, or implement a new feature in response to a request, the log of the code contribution should indicate the specific bug, error or feature that the code change is intended to resolve. Thus an exhaustive and auditible record is kept of each problem identified and the changes to the code taken to resolve it.
The OpenQuake engine web repository is gem/oq-engine
Programming language#
The core of the OpenQuake engine is developed in Python. Python is a high-level and open-source programming language extensively used in the scientific community which can run on almost all the operative systems currently available.
Basics of the Engine#
The implementation of the OpenQuake software officially started in Summer 2010 following the experience gained in GEM’s kick-off project GEM1 [GEM Foundation, 2010], during which an extensive appraisal of existing hazard and physical risk codes was performed [Danciu et al., 2010; Crowley et al., 2010b] and prototype hazard and risk software were selected, designed and implemented [Pagani et al., 2010; Crowley et al., 2010a].
The current version of the OpenQuake engine is Python code developed following the most common requirements of Open Source software development, such as a public repository, IRC channel and open mailing lists [1]. The source code, released under an open source software license, is freely and openly accessible on a web based repository (see github.com/gem) while the development process is managed so that the community can participate to the day by day development as well as in the mid- and long-term design process. The software development also leverages on a number of open source projects such as Celeryd and RabbitMQ, just to mention a few.
The hazard component of the engine largely relies on classes belonging to the OpenQuake Hazard library (see oq-hazardlib) a comprehensive library for performing state-of-the-art PSHA. This library has been designed and implemented following the successful collaboration and important lessons learnt working with the OpenSHA software and the developing teams at United States Geological Survey (USGS) and Southern California Earthquake Center (SCEC) in GEM1. The risk component of the engine was designed in GEM1, prototyped in Java and eventually coded in Python by the team operating at the GEM Model Facility. This scientific code was originally integrated with the engine, but in late 2012 it was extracted to form the OpenQuake Risk Library (see oq-risklib).
The basics of the OpenQuake engine hazard component#
The hazard component of the OpenQuake engine has been developed mostly following an object oriented programming paradigm taking, in some cases, concepts introduced in the development of OpenSHA, a seismic hazard analysis library developed within a joint SCEC-USGS collaboration (Field et al., 2003).
From a conceptual point of view, the main objects adopted in the development of the oq- hazardlib follows quite closely the classical schematic proposed by Reiter (1991) i.e. a seismic source, a ground shaking intensity model and a calculator that using this information computes the hazard at the site.
The OpenQuake engine builds on top of oq-hazardlib and expands this concept by taking into account not just the essential objects needed to compute the hazard at a site discussed before but also the parallelisation process used for large calculations.
Calculation workflows#
The hazard component of the OpenQuake engine provides four main calculation workflows (see next figure):
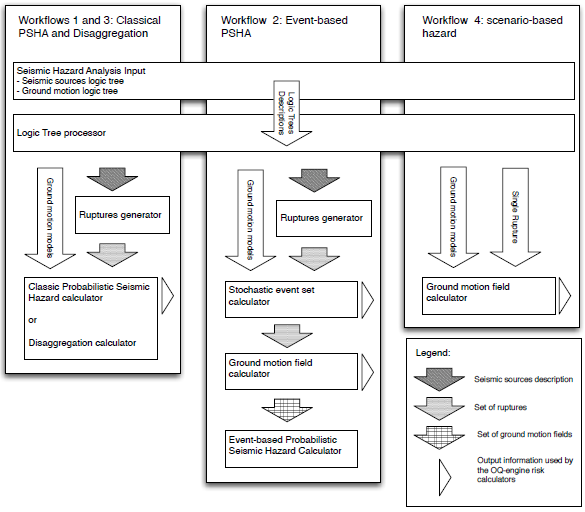
A schematic describing the main OpenQuake engine calculation workflows available in the hazard component.#
Classical Probabilistic Seismic Hazard Analysis (PSHA) calculates hazard curves, hazard maps, and uniform hazard spectra by solving the PSHA integration procedure, as proposed by Field et al. (2003). This is the usual approach adopted in regional/national-scale hazard assessment, as well as in site-specific studies. Using the risk component of the OpenQuake engine, the computed hazard curves can be combined with a vulnerability and exposure model to derive asset-specific loss exceedance curves and loss maps for various return periods. Such analyses are useful for comparative risk assessment between assets at different locations, or to understand the areas where mitigation actions should be concentrated. Crowley and Bommer (2006) suggest this methodology tends to overestimate losses at high return periods for portfolios of structures and recommend the use of methods capable to account for the spatial correlation of ground motion residuals.
Event-based PSHA computes stochastic event sets (i.e., synthetic catalogs of earthquake ruptures) and ground-motion fields for each rupture, possibly taking into account the spatial correlation of within-event residuals. This is essentially a Monte Carlo–based PSHA calculator (e.g. Musson, 2000). The computed synthetic catalogs can be used for comparisons against a real catalog, whereas hazard curves and hazard maps can be derived from post-processing the ground-motion fields (Ebel and Kafka, 1999). Ground- motion fields are essential input for loss estimations, whereby loss exceedance curves and loss maps are calculated for a collection of assets by combining a vulnerability and exposure model with these sets of ground-motion fields. Because the spatial correlation of the ground-motion residuals can be taken into account in this calculator, the losses to each asset can be summed per ground-motion field, and a total loss exceedance curve representative of the whole collection of assets can be derived. These results are important for deriving reliable estimates of the variance of the total losses.
Disaggregation, given a PSHA model, it computes the earthquake scenarios contributing the most to a given hazard level at a specific site (Bazzurro and Cornell, 1999). Currently this is done following the classical PSHA methodology; this functionality will be added to the event-based calculator in subsequent development phases.
Scenario-based Seismic Hazard Analysis (SHA), given an earthquake rupture and a ground-shaking model, a set of ground-motion fields can be computed. This is a typical use case for urban-scale loss analysis. This set of ground-motion fields can be employed with a fragility/vulnerability model to calculate distribution of damage/losses for a collection of assets. Such results are of importance for emergency management planning and for raising societal awareness of risk.
Testing and Quality Assurance#
Testing is an aspect carefully and diligently considered in the development of the OpenQuake engine. There are a several different reasons for the adoption of this approach.
The first and most practical one is dictated by the development process which involves experts from different disciplines (e.g. seismic hazard and information technology). In this context the use of a formal testing process is a way through which developers confirm the compliance of the tools developed against the requirements defined by the scientific team and it is also a process through which it can be demonstrated that the entire code fulfills minimum quality criteria (e.g. the code comply with the PEP 8 standard [2], the code before getting into the master repository is revised by at least one one separate developer and is clearly documented).
The second motivation relates to the specific goal of building a dynamic tool (i.e. offering a large flexibility and expandability) while constantly assuring the stability and reliability of the supported calculation workflows. The implementation of tests is usually done in parallel with code development, but tests are also added for example every time a bug is fixed. This improves the overall robustness and reliability of the code and reduces drastically the possibility of regressions.
The following approaches represent the four-level suite of tests applied to the OpenQuake engine and therefore provide high quality assurance standards. Further information can be found in the OpenQuake engine testing and quality assurance report (Pagani et al., 2014b).
Unit-testing and Testing against benchmark results
A testing methodology which checks discrete units of code against associated control data, expected behaviors and operating procedures. A special set of unit-tests are the ones systematically created for every Ground Shaking Intensity Model (GSIM) implemented (additional information about this specific topic is available within Chapter 4). The results provided by the OpenQuake engine are compared against benchmark results. Several of the tests defined by Thomas et al. (2010) are used to check the reliability and correctness of the results provided.
Tests against provided by other PSHA codes: simple cases
The result computed with the OpenQuake engine for simple models (e.g. one area source) are compared against the results calculated using independent PSHA software.
Tests against provided by other PSHA codes: national or regional PSHA input models
The result computed with the OpenQuake engine using national or regional models are compared against the results calculated using independent PSHA software.