The concept of rupture collection¶
Event based calculations differ from classical calculations because they produce visible ruptures, which can be exported and made accessible to the user. On the contrary, in a classical calculation, the underlying ruptures only live in memory and are never saved in the datastore, nor are exportable. The limitation is fundamentally a technical one: in the case of an event based calculation only a small fraction of the ruptures contained in a source are actually generated, so it is possible to store them. In a classical calculation all ruptures are generated and there are so many millions of them that it is impractical to save them. For this reason they live in memory, they are used to produce the hazard curves and immediately discarded right after. Perhaps in the future we will be able to overcome the technical limitations and to store the ruptures also for classical calculations; at the moment it is not so. Therefore here we will only document how the ruptures are stored for event based calculations.
Because the computation is organized by tectonic region model the ruptures are naturally organized by tectonic region model. In the case of full enumeration there is a one-to-one correspondence between rupture collections and tectonic region models. In the case of sampling, instead, there is a many-to-one correspondence, i.e. multiple rupture collections are associated to the same tectonic region model. The number is given by the number of samples for the source model to which the tectonic region model belongs. The total number of rupture collections is
sum(num_tectonic_region_models * num_samples for sm in source_models)
The number of collections is greater (or equal) than the number of realizations; it is equal only when the number of tectonic region models per source model is 1.
It should be noted that one or more collections could be empty in the presence of logic tree reduction. Banally, if there are no sources for a given tectonic region, even before filtering and rupture generation, it is clear the the rupture collection corresponding to the tectonic region model will be empty.
An example with a large logic tree (full enumeration)¶
Here we will show the concept of rupture collection works in practice in a SHARE-like calculation. We will consider the example of our QA test qa_tests_data.event_based_risk.case_4. This is an artificial test, obtained by a real computation for Turkey by reducing a lot the source model and the parameters (for instance the investigation time is 10 years whereas originally it was 10,000 years) so that it can run in less than a minute but still retains some of the complexities of the original calculation. It is also a perfect example to explain the intricacies of the logic tree reduction.
If you run oq info -r on that example you will get a number of warning messages, such as:
WARNING:root:Could not find sources close to the sites in models/src/as_model.xml sm_lt_path=('AreaSource',), maximum_distance=200.0 km, TRT=Shield
WARNING:root:Could not find sources close to the sites in models/src/as_model.xml sm_lt_path=('AreaSource',), maximum_distance=200.0 km, TRT=Subduction Interface
WARNING:root:Could not find sources close to the sites in models/src/as_model.xml sm_lt_path=('AreaSource',), maximum_distance=200.0 km, TRT=Subduction IntraSlab
WARNING:root:Could not find sources close to the sites in models/src/as_model.xml sm_lt_path=('AreaSource',), maximum_distance=200.0 km, TRT=Volcanic
WARNING:root:Could not find sources close to the sites in models/src/as_model.xml sm_lt_path=('AreaSource',), maximum_distance=200.0 km, TRT=Stable Shallow Crust
Such warnings comes from the source filtering routine. They simply tell us that a lot of tectonic region types will not contribute to the logic tree because they are being filtered away. Later warnings are even more explicit:
WARNING:root:Reducing the logic tree of models/src/as_model.xml from 640 to 4 realizations
WARNING:root:Reducing the logic tree of models/src/fsbg_model.xml from 40 to 4 realizations
WARNING:root:Reducing the logic tree of models/src/ss_model.xml from 4 to 0 realizations
WARNING:root:No realizations for SeiFaCrust, models/src/ss_model.xml
WARNING:root:Some source models are not contributing, weights are being rescaled
This is a case where an apparently complex logic tree has been reduced to a simple one. The full logic tree is composed by three GMPE logic trees, one for each source model. The first one (for sources coming from the file as_model.xml) has been reduced from 640 potential realizations to 4 effective realizations; the second one (for sources coming from the file fsbg_model.xml) has been reduced from 40 potential realizations to 4 effective realizations; the last one (for sources coming from the file ss_model.xml) has been completely removed, since after filtering there are no sources compling from ss_model.xml, aka the SeiFaCrust model. So, there are no effective realizations belonging to it and the weights of the source model logic tree have to be rescaled, otherwise their sum would not be one. The composition of the composite source model, after filtering and rupture generation becomes:
<CompositionInfo
AreaSource, models/src/as_model.xml, trt=[0, 1, 2, 3, 4, 5], weight=0.500: 4 realization(s)
FaultSourceAndBackground, models/src/fsbg_model.xml, trt=[6, 7, 8, 9], weight=0.200: 4 realization(s)
SeiFaCrust, models/src/ss_model.xml, trt=[10], weight=0.300: 0 realization(s)>
It is interesting to notice that the engine is smart enough to reduce the logic even before filtering and rupture generation, by simply looking at the sources. The full SHARE GMPE logic tree has potentially 1280 realizations, but by looking at the sources contained in the reduced AreaSource source model, the engine infers that at most only 640 realizations can be relevant; that means that there is a missing tectonic region type with 2 GSIMs. For the FaultSourceAndBackground model only 40 realizations are expected upfront (it means that several tectonic region types are missing in the reduced source model) and for the SeiFaCrust model only 4 realizations are expected upfront (actually that source model has only a single source with tectonic region type “Active Shallow Crust”).
The report also contains the reduced RlzsAssoc object, which is the following:
<RlzsAssoc(8)
5,AkkarBommer2010: ['<0,AreaSource,AkkarBommer2010asc_@_@_@_@_@_@,w=0.25>']
5,CauzziFaccioli2008: ['<1,AreaSource,CauzziFaccioli2008asc_@_@_@_@_@_@,w=0.25>']
5,ChiouYoungs2008: ['<2,AreaSource,ChiouYoungs2008asc_@_@_@_@_@_@,w=0.142857142857>']
5,ZhaoEtAl2006Asc: ['<3,AreaSource,ZhaoEtAl2006Ascasc_@_@_@_@_@_@,w=0.0714285714286>']
9,AkkarBommer2010: ['<4,FaultSourceAndBackground,AkkarBommer2010asc_@_@_@_@_@_@,w=0.1>']
9,CauzziFaccioli2008: ['<5,FaultSourceAndBackground,CauzziFaccioli2008asc_@_@_@_@_@_@,w=0.1>']
9,ChiouYoungs2008: ['<6,FaultSourceAndBackground,ChiouYoungs2008asc_@_@_@_@_@_@,w=0.0571428571429>']
9,ZhaoEtAl2006Asc: ['<7,FaultSourceAndBackground,ZhaoEtAl2006Ascasc_@_@_@_@_@_@,w=0.0285714285714>']>
As you see, only two tectonic region models are relevant, the number 5 (i.e. the submodel of AreaSource with TRT=”Active Shallow Crust”) and the number 9 (i.e. the submodel of FaultSourceAndBackground with TRT=”Active Shallow Crust”).
The report contains information about the (non-empty) rupture collections; the same information can be extracted after the computation with the command
$ oq show <calc_id> ruptures_per_trt
Reduction of the logic tree when sampling is enabled¶
There are real life examples of very complex logic trees, even with more than 400,000 branches. In such situations it is impossible to perform a full computation. However, the engine allows to sample the branches of the complete logic tree. More precisely, for each branch sampled from the source model logic tree a branch of the GMPE logic tree is chosen randomly, by taking into account the weights in the GMPE logic tree file.
Suppose for instance that we set
number_of_logic_tree_samples = 4000
to sample 4,000 branches instead of 400,000. The expectation is that the computation will be 100 times faster. This is indeed the case for the classical calculator. However, for the event based calculator things are different. The point is that each sample of the source model must produce different ruptures, even if there is only one source model repeated 4,000 times, because of the inherent stochasticity of the process. Therefore the time spent in generating the needed amount of ruptures could make the calculator slower than using full enumeration: remember than when using full enumeration the ruptures of a given source model are generated exactly once, since each path is taken exactly once.
Notice that even if source model path is sampled several times, the model is parsed and sent to the workers only once. In particular if there is a single source model and number_of_logic_tree_samples = 4000, we generate effectively 1 source model realization and not 4,000 equivalent source model realizations, as we did in past (actually in the engine version 1.3). Then engine keeps track of how many times a model has been sampled (say N) and in the event based case it produce ruptures (with different seeds) by calling the appropriate hazardlib function N times. This is done inside the worker nodes. In the classical case, all the ruptures are identical and there are no seeds, so the computation is done only once, in an efficient way.
Convergency of the GMFs for non-trivial logic trees¶
In theory, the hazard curves produced by an event based calculation should converge to the curves produced by an equivalent classical calculation. In practice, if the parameters number_of_logic_tree_samples and ses_per_logic_tree_path (the product of them is the relevant one) are not large enough they may be different. The engine is able to compare the mean hazard curves and to see how well they converge. This is done automatically if the option mean_hazard_curves = true is set. Here is an example of how to generate and plot the curves for one of our QA tests (a case with bad convergence was chosen on purpose):
$ oq engine --run event_based/case_7/job.ini
<snip>
WARNING:root:Relative difference with the classical mean curves for IMT=SA(0.1): 51%
WARNING:root:Relative difference with the classical mean curves for IMT=PGA: 49%
<snip>
$ oq plot /tmp/cl/hazard.pik /tmp/hazard.pik --sites=0,1,2
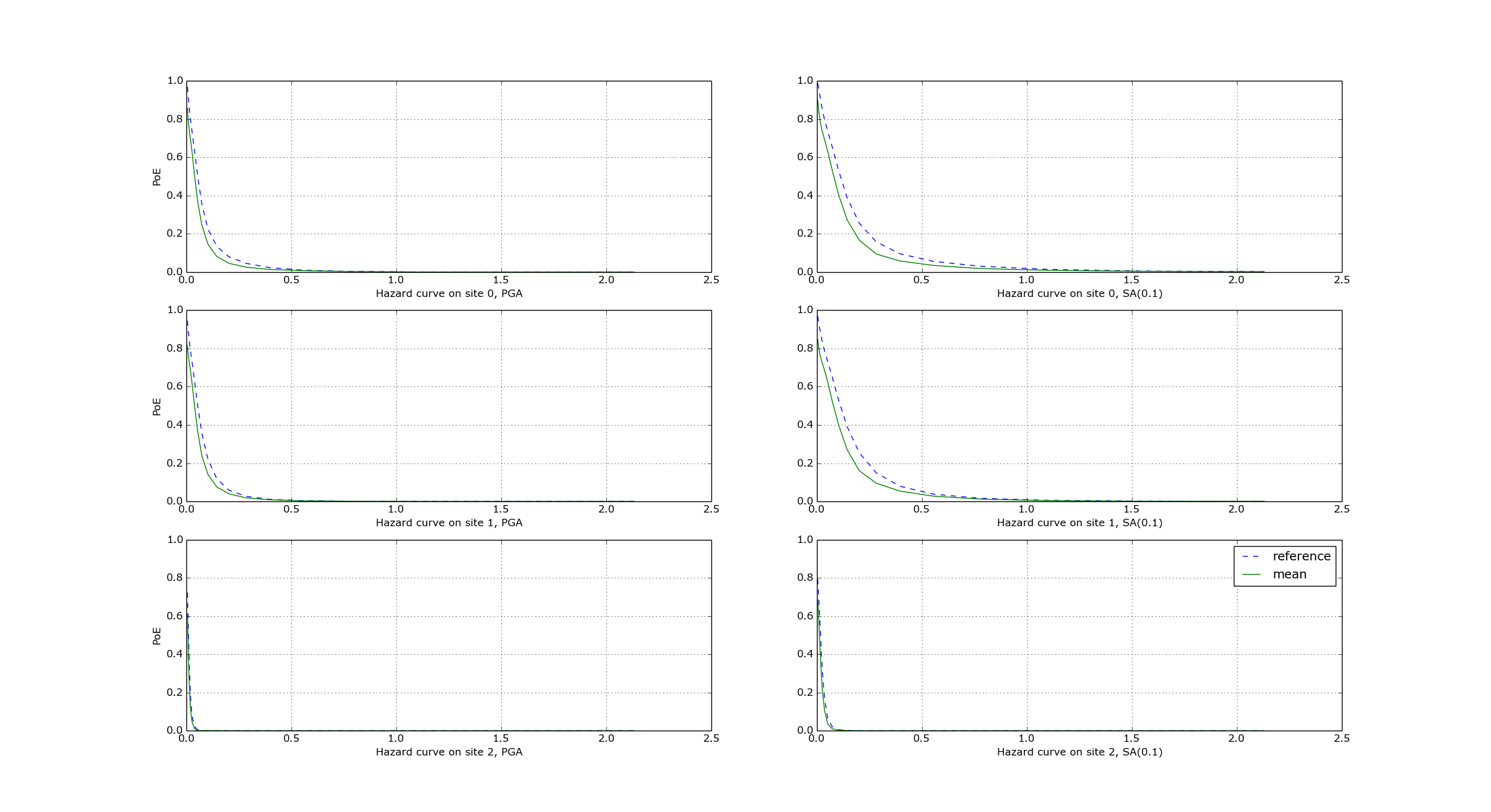
The relative difference between the classical and event based curves is computed by computing the relative difference between each point of the curves for each curve, and by taking the maximum, at least for probabilities of exceedence larger than 1% (for low values of the probability the convergency may be bad). For the details I suggest you to look at the code.